

Binnen Vechtstromen hoor je in de wandelgangen regelmatig langskomen dat de data niet op orde is. Dit blijft echter altijd bij een gevoel dat niet concreet gemaakt kan worden. Voor ons als ninja’s van de Digital Dojo reden om hier onderzoek naar te doen. Is de data inderdaad niet op orde, of valt dat wel mee? Waar ontbreekt data en waar is de data onjuist? Voor dit vraagstuk duiken we toepasselijk in de gegevens van duikers.
Bij dit vraagstuk gaan we direct ook verschillende pakketten met elkaar vergelijken op gebruiksgemak en toepasbaarheid, door parallel aan elkaar elk met een ander softwarepakket het onderzoek te doen.
De onderzochte softwarepakketten KNIME, Power BI en Dataiku
Het voordeel van het onderzoeken van de duikerdata is dat de relevante domeinkennis aanwezig is, dankzij de geo-achtergrond van Carolien. We hebben er daarom voor gekozen om Carolien vooral de rol van domeinspecialist te laten vervullen, terwijl Peter, Dennie en Matthijs het onderzoek vormgaven in respectievelijk de softwarepakketten KNIME, Power BI en Dataiku.
Hoe zijn we begonnen?
Carolien heeft eerst de duikerdata geëxporteerd en onder handen genomen. Hierbij zijn kolommen verwijderd die in alle gevallen leeg zijn of in alle gevallen gevuld zijn met dezelfde waarde. Ook zijn de domeintabellen geëxporteerd. Zo hoeven we in het verdere onderzoek niet te werken met een duiker met vorm 3 van het materiaal 20, maar kunnen we gebruik maken van een eivormige duiker van pvc.
Na deze vertaling zijn we met de data aan de slag gegaan om inzicht te krijgen in de gegevens door verschillende overzichten te maken. Hieronder zijn een aantal van deze overzichten terug te vinden. In de overzichten zijn de duikers met status “niet meer aanwezig” en “OOWS” weggelaten, aangezien fouten of ontbrekende gegevens bij deze duikers niet meer relevant zijn.
Wat hebben we gevonden?
Bestaande controles
De geospecialisten doen zelf ook al een aantal controles op de gegevens. Eén van deze controles wordt gedaan op hoogte van de kokerbodem van de duiker (bovenonderkant, kortweg bok). Deze hoogte wordt gemeten ten opzichte van het NAP. Hierbij mag het verschil tussen de hoogte bovenstrooms (bos) en de hoogte benedenstrooms (bes) niet meer zijn dan een halve meter.
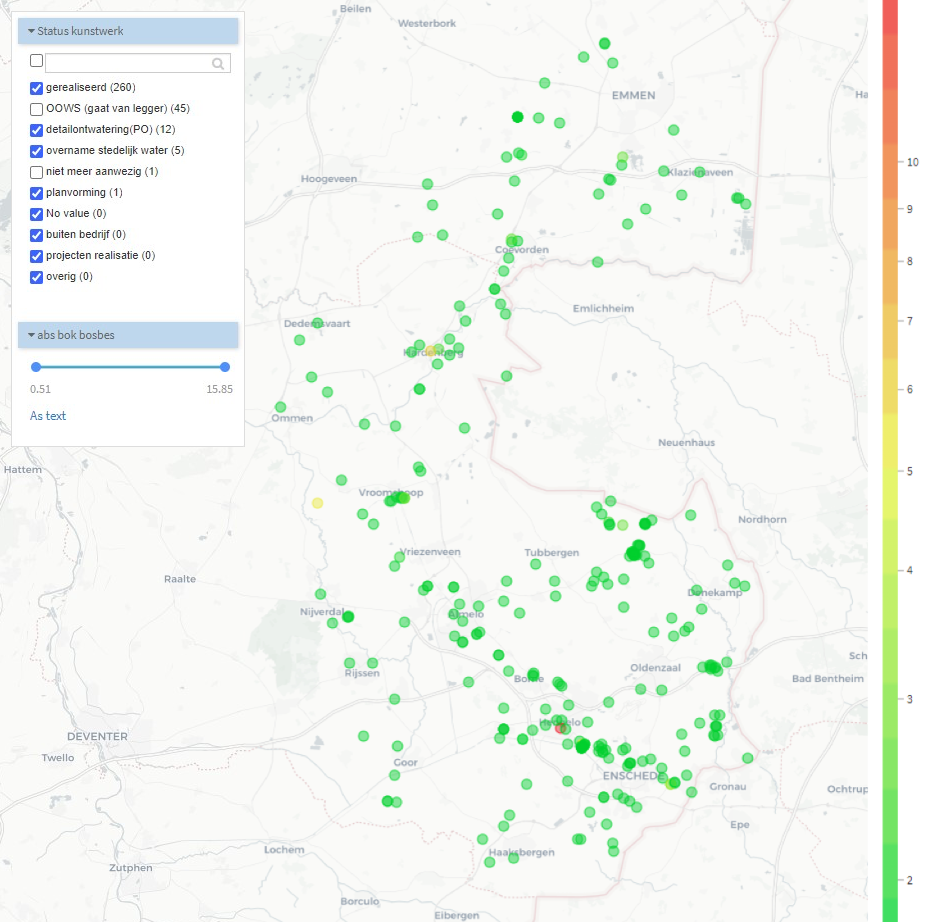
290 duikers hebben een te groot verschil in bok bos-bes. De kleur geeft aan hoe groot het verschil is.
Naast het verschil in bok bos-bes worden er ook al controles gedaan op vorm. Zo moet bij een ronde duiker de hoogte gelijk zijn aan de breedte en mag dat bij een ellipsvormige duiker juist niet het geval zijn. In totaal geven de bestaande controles 308 duikers terug waar iets aan mankeert. Dat is zo’n 1,5% van de gecontroleerde duikers.
Ontbrekende waarden
Vervolgens hebben we zelf nog controles gedaan, om te beginnen op ontbrekende waarden. Duikers kunnen voorzien zijn van een afsluiter, zowel bovenstrooms als benedenstrooms. In 1.149 gevallen is echter geen waarde ingevuld, of de waarde “onbekend”.
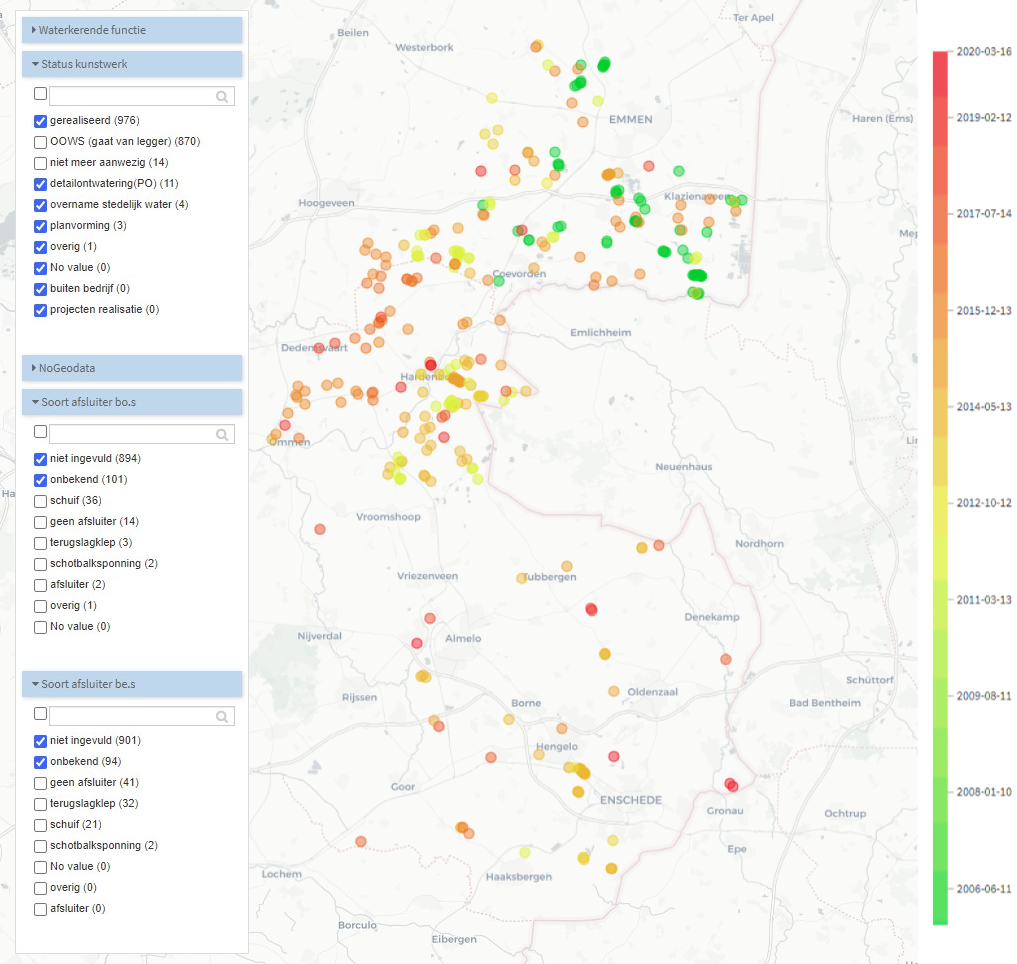
De 1.149 duikers met ontbrekende of onbekende informatie over de afsluiters. De kleur geeft aan wanneer de duikerdata is ingewonnen.
Bij duikers wordt door middel van de waarde 99,99 aangegeven dat een waarde niet te meten is. Bij het verdere gebruik van de duikerdata, bijvoorbeeld door de hydrologen, wordt dit gegeven in dat geval niet gebruikt. We zijn echter 18 duikers tegengekomen waar afwijkende waarden zijn gebruikt, bijvoorbeeld 99,0 of 99,59. Navraag leert ons dat dit soms voortkomt uit beperkte mogelijkheden bij de invoer. Bij het verdere gebruik van de duikerdata kan dit echter voor vreemde situaties zorgen als deze waarden mee worden genomen in berekeningen.
Ook het aantal kokers komt terug in de analyse op ontbrekende gegevens. In meer dan 7.500 gevallen is dit niet vastgelegd. Hier komt de domeinkennis goed van pas: vroeger werden parallelle duikers als één duiker vastgelegd, waarbij het aantal kokers op 2 werd gezet. Tegenwoordig worden parallelle duikers altijd apart geregistreerd en heeft het aantal kokers geen toegevoegde waarde meer. Het aantal kokers ontbreekt dus wel bij veel duikers, maar is niet meer relevant. Ons advies is om te onderzoeken of dit gegeven kan worden verwijderd uit de duikerdata.
Los van het aantal kokers ontbreken er bij 1.164 duikers een of meer gegevens. Dit komt neer op zo’n 6% van het totaal.
Gemeten vs. Gis
Bij duikers wordt de lengte in drie varianten vastgelegd: de lengte op de legger, de door de landmeter gemeten lengte en de berekende lengte zoals de duiker op de kaart is getekend. Op deze lengtes hebben we analyses gedaan, waar bij 1.353 duikers een verschil van meer dan 15 cm werd geconstateerd tussen de gemeten lengte en de berekende lengte. Ruim 7% van de duikers is dus naar boven gekomen bij deze controle.
Fout op de legger
We hebben ook onderzocht in hoeverre gegevens op de legger zijn vastgelegd en of de waarden op de legger overeenkomen met de gemeten waarden. In 2.128 gevallen ontbreken er een of meer waarden op de legger. Daarnaast werden nog 1.604 duikers gevonden waarbij gemeten waarden meer dan een halve meter verschillen van de legger.
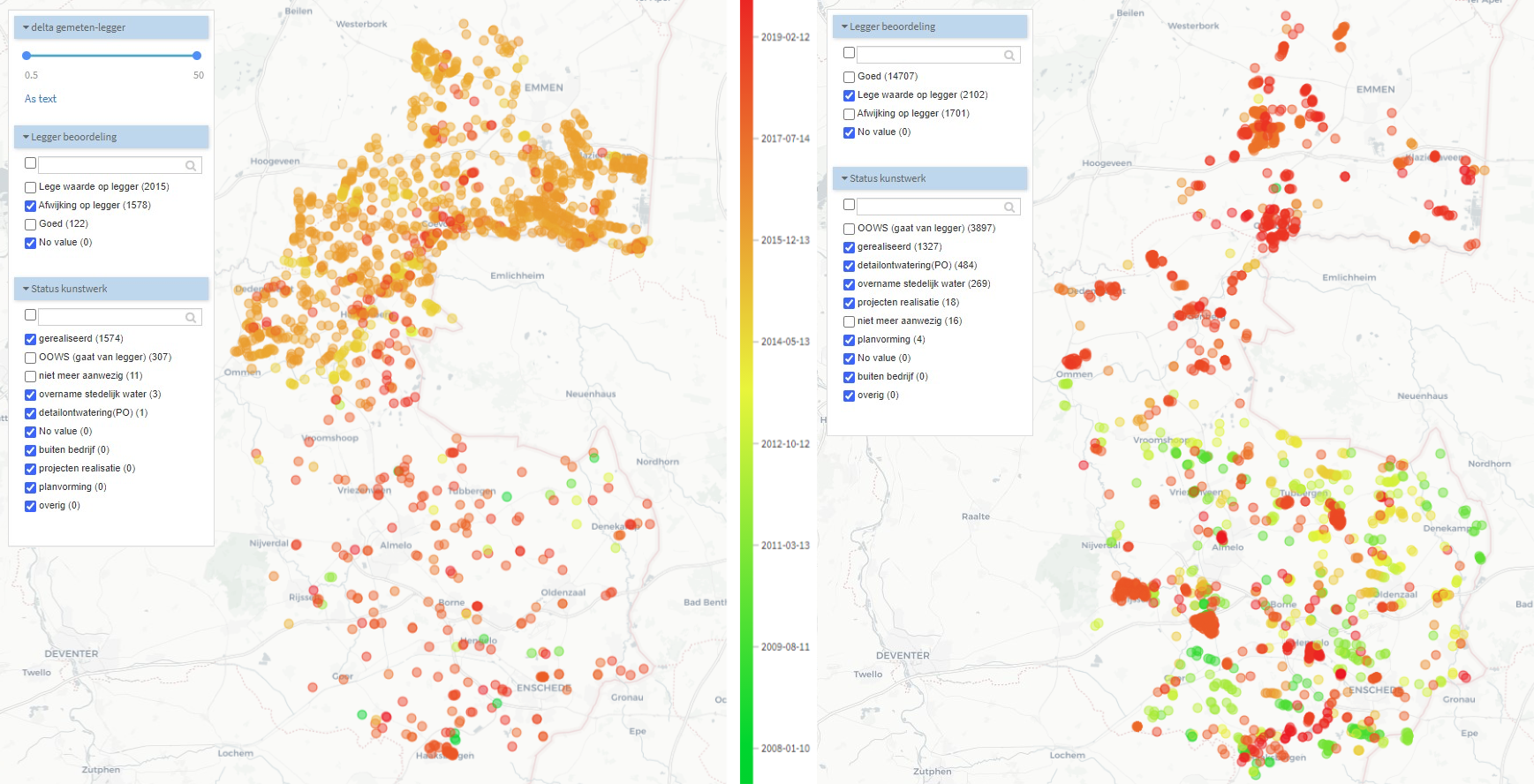
Links een kaart met duikers waarbij de waarden op de legger afwijken van de gemeten waarden. Rechts een kaart met duikers waarbij waarden op de legger niet gevuld zijn. In beide gevallen is de kleur gebaseerd op de datum waarop de duikerdata is ingewonnen.
In totaal zijn er 3.732 duikers waarbij de controles op de legger een aandachtspunt opleveren, zo’n 20% van de meegenomen duikers.
Clusters en outliers
Ten slotte hebben we met behulp van k-means clustering naar onwaarschijnlijke waarden (zogenaamde outliers) gezocht. Met deze methode worden de duikers in clusters gegroepeerd waarin duikers sterk op elkaar lijken, op basis van enkele aangewezen kenmerken. Duikers die niet goed in een van de clusters passen, worden gemarkeerd als outlier. We hebben naar outliers gezocht voor de combinatie van inwendige breedte en hoogte met de vorm en voor de combinatie van lengte met materiaal. Bij deze laatste combinatie is mooi te zien dat een pvc duiker van 100 meter onwaarschijnlijk is, terwijl een betonnen duiker van 100 meter wel binnen een van de clusters past.
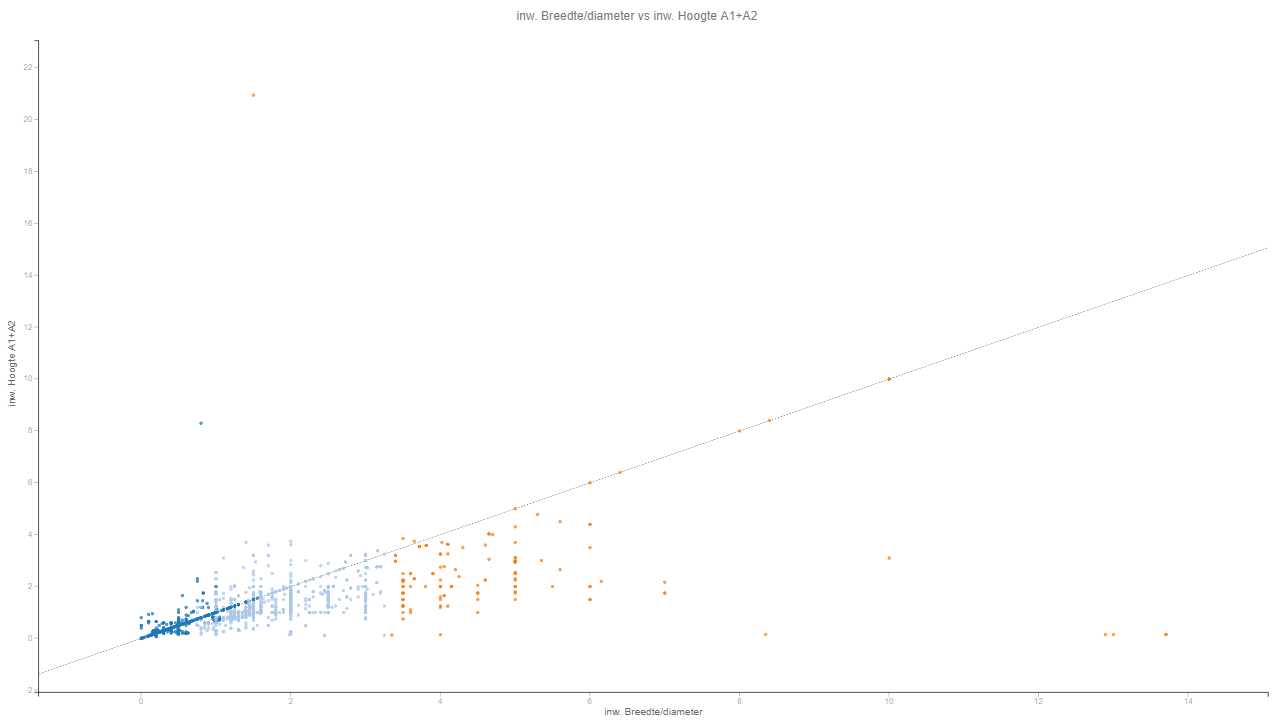
Duikers gegroepeerd op basis van inwendige breedte en hoogte, gecombineerd met de vorm. De oranje punten zijn de duikers die als outlier gemarkeerd zijn.
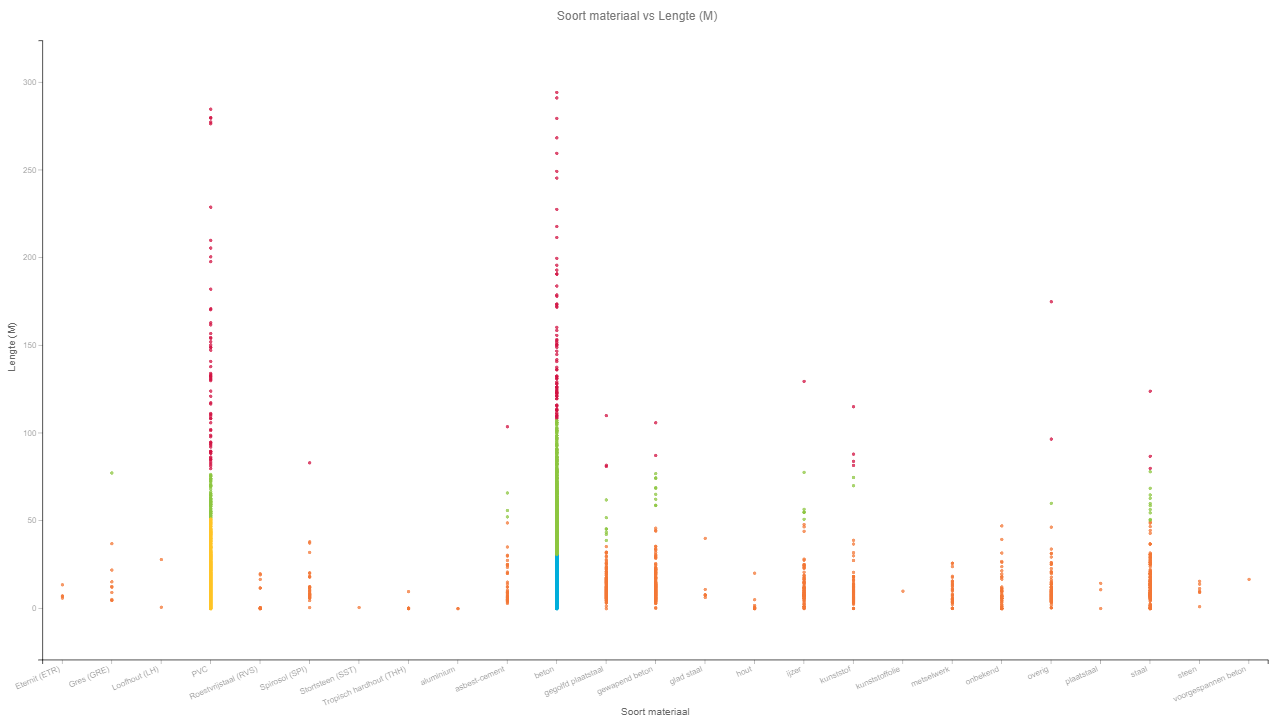
Duikers gegroepeerd op basis van lengte en materiaal. De paarse punten zijn de gevonden outliers.
Is de data op orde?
Alle controles samen leveren in totaal 6.067 duikers op waarbij er een of meer aandachtspunten gevonden zijn, ongeveer 33% van het totaal. Topologische controles kunnen mogelijk nog meer aandachtspunten opleveren, maar dit viel buiten de scope van deze opdracht.
De 33% geeft een beeld in hoeverre de data op orde is wat de duikers betreft. Hier blijft echter nog wel de vraag welk percentage aan juiste data je nastreeft. De kosten van het op orde houden van de data nemen steeds sneller toe naarmate je een hoger percentage nastreeft. Overigens hebben we alleen zaken als aandachtspunt aangemerkt als deze boven een bepaalde drempel kwamen. Bij het bepalen welke datakwaliteit de organisatie nastreeft, zullen deze drempels ook bekeken en waar nodig aangepast moeten worden.
Na de presentatie van de resultaten aan de betrokkenen hebben we Bas Maathuis, specialist op het gebied van het beheer van geo-informatie, gevraagd wat hij van deze resultaten vindt:
"Absoluut zinvol om op een andere manier naar data te kijken en te zien welke gegevens dan boven water komen. Ik denk wel dat je met concretere achtergrondinformatie de uitkomsten veel beter kunt duiden. Uiteindelijk waren er voor mij niet veel verrassingen, maar ik vond het wel heel leuk dat anderen, zonder achtergrondinformatie, met deze data gaan stoeien." — Bas Maathuis, medewerker beheer en geo-informatie
Dat er niet veel verrassingen bij de resultaten zaten, roept bij ons de vraag op of er wel genoeg aandacht wordt besteed aan het daadwerkelijk corrigeren van gevonden aandachtspunten. Daarom adviseren we de organisatie om te bepalen welk kwaliteitsniveau we na willen streven en welke drempelwaarden daarbij toegepast moeten worden, en om tijd te investeren in het corrigeren van brondata.
En hoe zit het met de pakketvergelijking?
Elk pakket heeft zo zijn sterke kanten. Het vertalen van de data door middel van domeintabellen en het doen van berekeningen ging het eenvoudigst in KNIME. Bij het maken van overzichten en dashboards en het verkrijgen van inzicht in de data kwam Dataiku juist weer naar voren als beste optie. Voor het ontsluiten van modellen en dashboards past Power BI weer beter binnen ons applicatielandschap. Vanwege het ontsluiten van modellen en dashboards is de kans groot dat we soortgelijke onderzoeken in de toekomst vooral met Power BI gaan uitvoeren.
Auteur: Peter Buisman









