

Probleem
Dagelijks is iedereen in onze organisatie tijd aan het verspelen met het zoeken naar de juiste informatie. Dit komt deels door de diversiteit aan opslagmogelijkheden die we als organisatie bieden (en de onduidelijke richtlijnen en vrijheid binnen deze mogelijkheden). Hierdoor moet je je ten eerste al afvragen: waar moet ik zoeken? Deels is informatie ook slecht vindbaar doordat we zelf de informatie niet goed registreren en/of opslaan. Hierdoor is het moeilijker of niet vindbaar voor anderen (of soms zelfs jezelf). Dit beperkt vervolgens ook weer de mogelijkheden hoe je kunt/moet zoeken om informatie terug te vinden.
Een groot gedeelte van onze informatie moeten we als overheidsorganisatie verplicht archiveren, soms zelfs tot in de lengte der dagen. Dit doen we in ons archiveringssysteem. En net als bijna alles tegenwoordig is ook dit een self-service systeem. Archiveer je eigen documenten, want jij weet als beste waar het over gaat. Hier ontstaat echter nog een probleem. Het systeem is gebruiksonvriendelijk, veel te tijdrovend en mensen hebben niet genoeg belang om al hun documenten te archiveren. Dit gebeurt dan ook vaak niet, of op een manier waardoor documenten niet of slecht terug te vinden zijn.
Oplossingsrichting
Het eerste probleem, waar moet ik mijn gegevens opslaan, bemoeien we ons niet mee (tenzij iemand met een goede vraag bij ons komt :)). Hier lopen initiatieven voor zoals momenteel de implementatie van Teams. Het tweede dachten wij echter een bijdrage aan te kunnen leveren. Met Outsystems een gebruiksvriendelijke schil bouwen om ons archiefsysteem heen, hierbij gebruik makend van machine learning voor het interpreteren en classificeren van documenten.
Samen met onze informatiebeheerafdeling zijn we daarom een pilot gestart die zich in eerste instantie alleen richt op projectdocumentatie. Hier ligt er namelijk een hoop achterstallig archiefwerk en dit maakt de scope wat beperkter. Als we goede resultaten kunnen boeken op projectgebied is dit ook mogelijk op andere gebieden. Hiernaast hebben we besloten om de koppeling met ons archiefsysteem niet mee te nemen. Hiervoor zijn bestaande en bewezen koppelmogelijkheden. Voor ons valt hier dus niets te bewijzen en onderzoeken.
Werkwijze
Samen met Wil en Anne-Jan van onze informatiebeheerafdeling hebben we in kaart gebracht wat de problemen precies waren en welke oplossingsrichting we op wilden gaan. Uiteindelijk kwamen we als oplossing uit op onderstaande afbeelding.
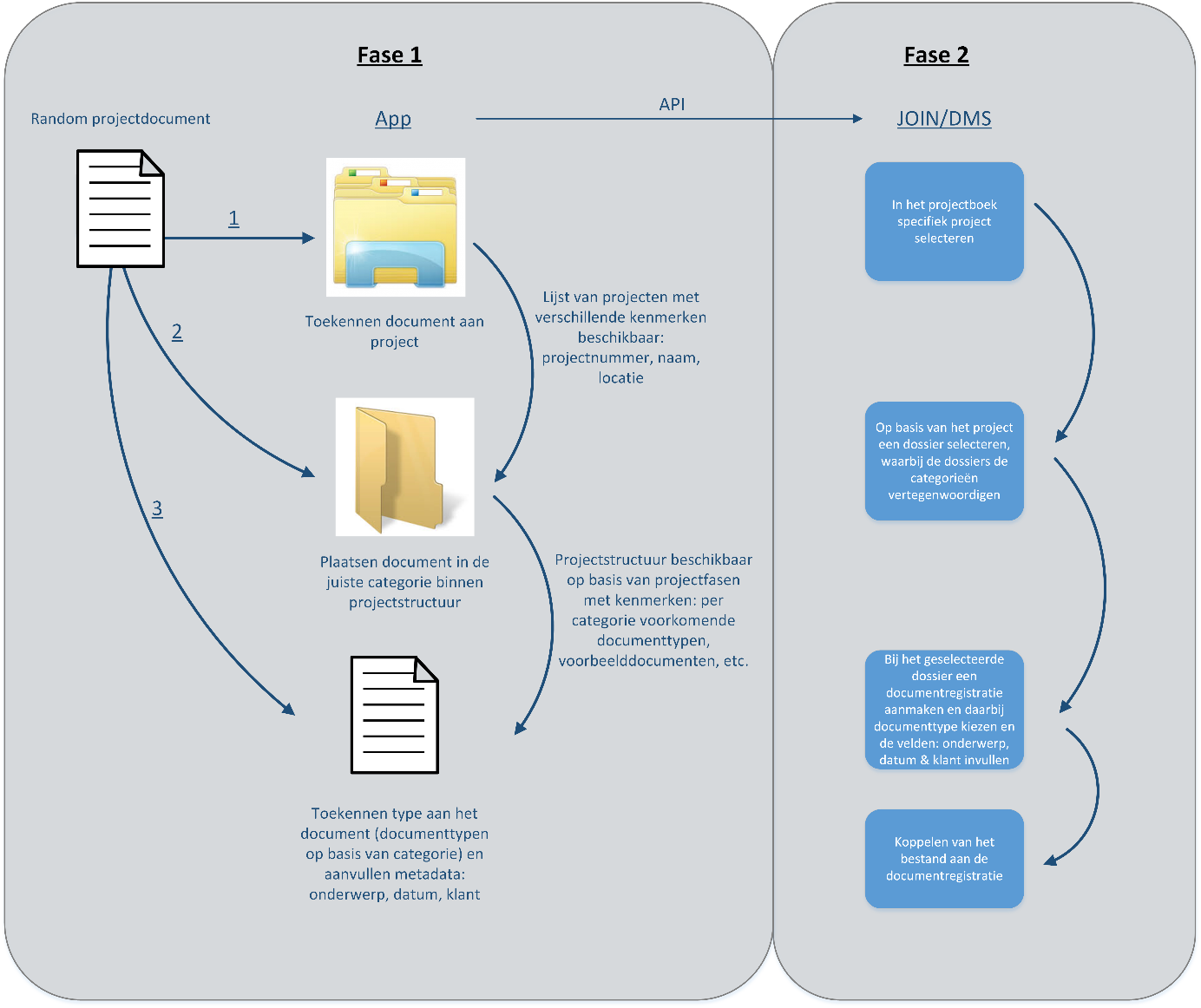
Gewenste oplossingsrichting
Hierna hebben wij ons als Dojo verdiept in de NLP (Natural Language Processing) en de bestaande mogelijkheden daarbij. Hoe leer je een computermodel grote hoeveelheden taal te verwerken en te analyseren? Veel partijen zoals Microsoft, Google, AWS bieden hiervoor al modellen aan. Geen enkele partij echter voor de Nederlandse taal. Toevallig kwamen we in de tussentijd in contact met Ilionx. Zij waren bezig met het ontwikkelen van een model toegespitst op de Nederlandse taal. Vanaf dat moment zijn we samen met hen verder opgetrokken en hebben we hun model verder getraind met onze organisatiespecifieke documenten.
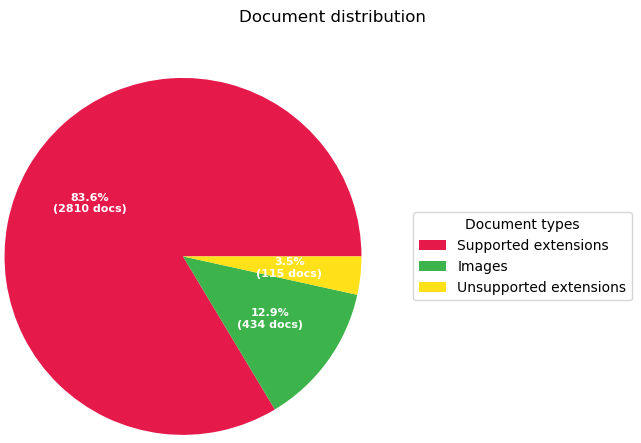
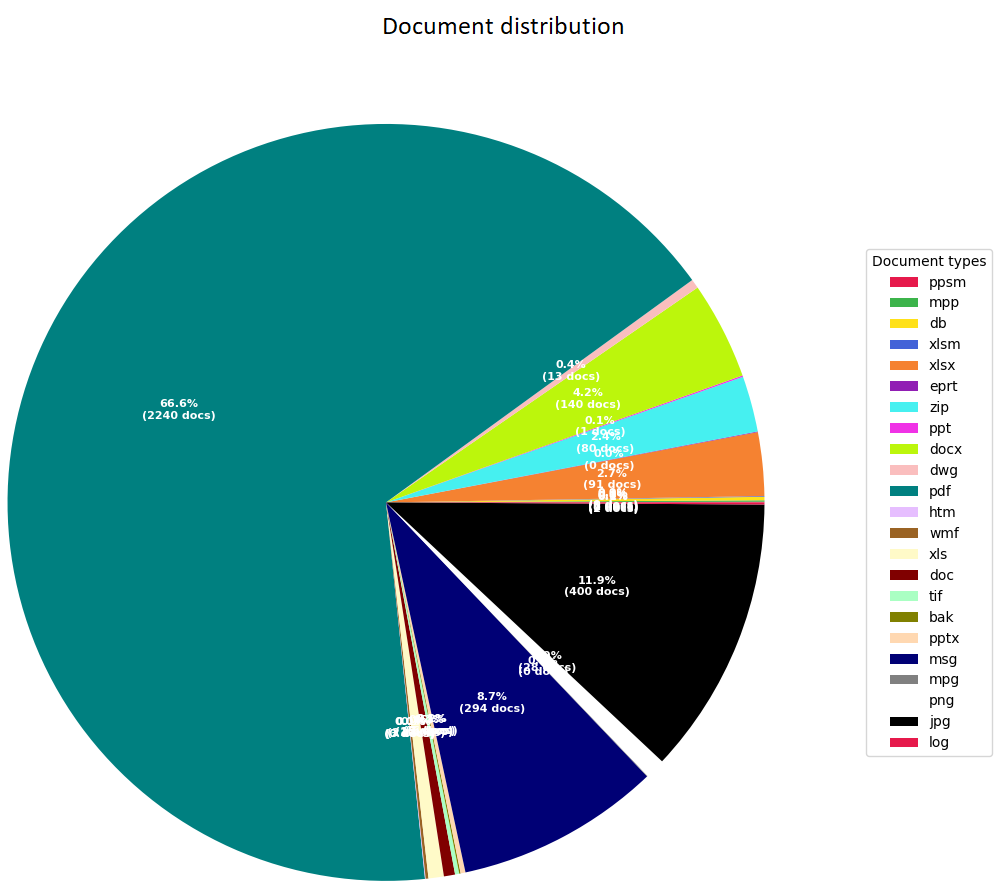
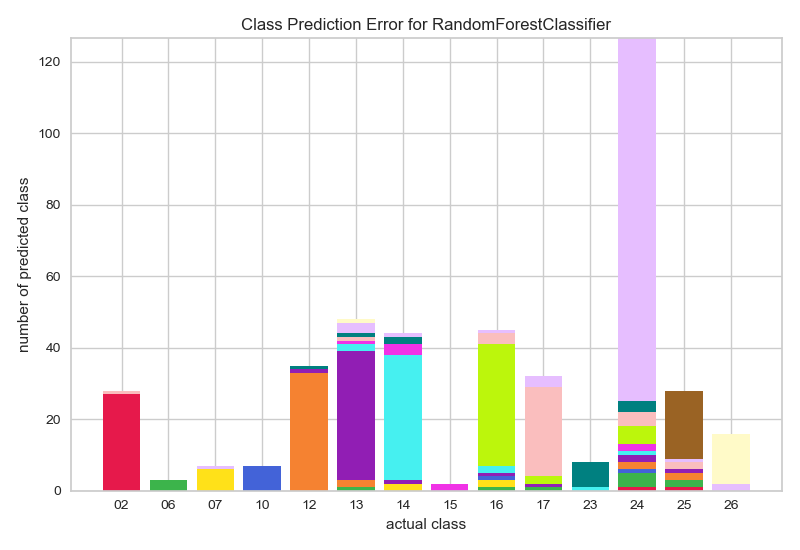
Terwijl Ilionx bezig ging met het verder ontwikkelen van het machine learning model zijn wij zelf verder gegaan aan het bouwen van een applicatie die eenvoudig en snel in gebruik is en op de juiste momenten het machine learning model van Ilionx aanroept.
Resultaten
We hebben momenteel een eerste testversie opgeleverd aan onze collega's van informatiebeheer. Zij gaan de applicatie uitgebreid testen en aan de hand daarvan gaan we bepalen hoe we verder gaan.
Conclusie
Momenteel kunnen we nog geen definitieve conclusies trekken, deze volgen in een vervolgverslag.
Wel kunnen we inmiddels zeggen dat er wat betreft classificatie nog ruimte voor verbetering is, maar dat ook goed te verklaren is waarom. Het model is namelijk getraind met (te) weinig gegevens. Zo hadden 6 van de 26 projectmappen die we aangeleverd hebben gekregen geen enkel document, 5 van de 26 te weinig documenten (minder dan 25) en leken enkele projectmappen vervuild met verkeerde documenten. Dit heeft als gevolg dat het model deze mappen niet of niet goed kan voorspellen. We hebben de applicatie echter zo ingericht dat de controles over de documenten, die nu in de testfase dus ook plaats gaan vinden, als feedback teruggestuurd worden naar het model. Zo blijft het model bijleren en zullen de voorspellingen steeds beter worden. Van de mappen waar wel genoeg documenten in stonden wordt nu ongeveer 81% goed voorspeld.
Met deze wetenschap kan er nu uitgebreid getest gaan worden en gaan we daarna samen met onze collega's bepalen hoe en of we dit verder door gaan ontwikkelen voor de organisatie. Wat ons en onze partner Ilionx betreft zijn er in ieder geval nog mogelijkheden genoeg om te verkennen!
Meer informatie?
Wil je meer weten over de gehanteerde machine learning modellen? Of de data pipeline? De gebruikte forgecomponenten van Outsystems? Stuur dan ook vooral een berichtje!
Auteur: Dennie Kamp









