

Probleem
Als overheidsorganisatie is waterschap Vechtstromen verplicht om Europese aanbestedingen te categoriseren naar CPV-codes. CPV staat voor Common Procurement Vocabulary. PIANOo (expertisecentrum aanbesteden) omschrijft dit als gemeenschappelijke woordenlijst waarin alle mogelijke soorten overheidsopdrachten voor diensten, leveringen en werken een eigen code hebben gekregen.
Om achteraf te kunnen controleren of opdrachten toch aanbesteed hadden moeten worden, moeten naast de Europese aanbestedingen ook alle overige opdrachten worden gecategoriseerd door middel van een CPV-code. Er zijn echter meer dan 200 CPV-codes waaruit gekozen kan worden, waarvan er in principe maar één juist is voor elk soort opdracht.
Om bestellers hierin te ondersteunen zijn de CPV-codes per leverancier ingeperkt, maar toch worden er nog veel fouten gemaakt. Hierdoor zijn er achteraf arbeidsintensieve controles nodig en moet er veel worden gecorrigeerd.
Aandeel bestellingen per CPV-code
Oplossingsrichting
Er zijn twee problemen waarvoor een oplossing gewenst is. Enerzijds de fouten die gemaakt worden bij de keuze van de CPV-code en anderzijds de hoeveelheid werk die nodig is bij het controleren van de gekozen CPV-codes. Voor beide problemen biedt een model dat de CPV-code kan voorspellen toegevoegde waarde.
“Door het inzetten van nieuwe technieken zoals Data Science is het mogelijk om de uitgebreide keuzemogelijkheid van een CPV-code te vereenvoudigen tot een keuze van bijvoorbeeld maximaal 3 codes. Dit scheelt tijd voor de bestellers bij het aanmaken van de order plus het verkleint het risico op een verkeerde keuze van CPV-code. Verder scheelt dit in het aantal te corrigeren boekingen bij de uitvoering van de spendanalyse.” — Vera Koster, adviseur inkoop.
Werkwijze
Eerst is zoveel mogelijk informatie met betrekking tot bestellingen uit het financieel systeem opgehaald, zoals bijvoorbeeld de leverancier, de besteller, het moment van bestellen, de financiële boekingscombinatie en de omschrijving. Uiteraard is ook de vastgelegde CPV-code opgehaald, waarbij alleen codes zijn meegenomen die zijn gecontroleerd door inkoopmedewerkers.
Vervolgens hebben we de gegevens waar nodig bewerkt, door bijvoorbeeld numerieke codes om te zetten naar tekst. Dit is nodig omdat het model anders probeert te rekenen met de numerieke codes en er bijvoorbeeld van uitgaat dat 42410 minder is dan 42411, terwijl dit twee verschillende kostensoorten zijn waarbij er niet één meer of minder is dan de ander.
Op de omschrijvingen op de bestellingen is tekstanalyse toegepast door middel van TF-IDF (Term Frequency - Inverse Document Frequency). Hierbij wordt geteld hoe vaak woorden voorkomen (term frequency) en dit aantal daarna afgezet tegen de mate waarin dat woord voorkomt in andere teksten (inverse document frequency). Zo kan worden bepaald welke woorden in een omschrijving belangrijk zijn en welke woorden weinig. In de zin ‘plaatsing van een zonnepaneel’ bijvoorbeeld, zijn ‘plaatsing’ en ‘zonnepaneel’ belangrijk, terwijl ‘van’ en ‘een’ weinig zeggen.
Tussenresultaten
Op de bewerkte en geanalyseerde data hebben we verschillende modellen ‘losgelaten’, waarvan de Decision Tree en Naive Bayes veelbelovende resultaten lieten zien van respectievelijk 90 en 87 procent betrouwbaarheid. Van deze modellen is de keuze gevallen op Naive Bayes, omdat die beter zou gaan presteren bij nieuwe leveranciers en bestellers.
Om dit model goed te toetsen aan de praktijk is vervolgens het rapport opgevraagd dat is gebruikt bij de laatste spend analyse (waar de controle op CPV-codes een onderdeel van is) en is het model toegepast op die gegevens. Helaas bleek daarbij dat bij de handmatige controle alleen bestellingen worden gecontroleerd die boven een bepaald drempelbedrag vallen. Veel van deze bestellingen hebben echter geen regelomschrijving, terwijl die over alle bestellingen heen gezien vaak wel gevuld is. De regelomschrijving had een belangrijk aandeel in de uitkomsten van het model, waardoor het model op het rapport voor de spend analyse maar een betrouwbaarheid van ongeveer 60% liet zien.
Verwerking tussenresultaten
Om de resultaten te verbeteren, hebben we meer gegevens opgehaald om ontbrekende regelomschrijvingen te kunnen compenseren, zoals bijvoorbeeld de omschrijving van de factuur. Daarnaast is de tekstanalyse uitgebreid en zetten we woorden nu om naar vectoren, gebaseerd op een grote verzameling woordvectoren. Met de overige gegevens wordt dit voor elke (regel van een) bestelling gecombineerd tot één vector.
Met deze vectoren wordt nu door middel van Cosine Similarity gezocht naar vergelijkbare bestellingen en wordt de CPV-code van de meest overeenkomende bestelling teruggegeven.
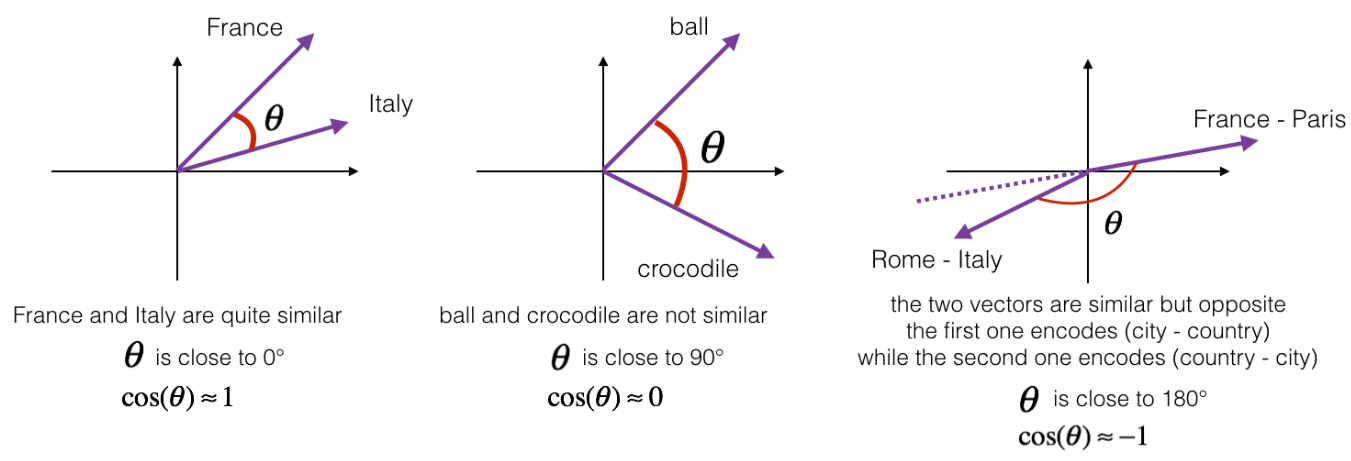
Visuele uitleg Cosine Similarity
In ruim 93% van de gevallen kan het model nu de CPV-code goed voorspellen. In ruim 96% van de gevallen zit de juiste CPV-code tussen de drie meest waarschijnlijke CPV-codes die het model teruggeeft.
Conclusie
Na de aanpassingen is het model betrouwbaar genoeg om toe te passen bij de controle op de CPV-code, waardoor er nog maar een klein deel van de CPV-codes door een inkoopmedewerker beoordeeld hoeft te worden.
Het model heeft ook potentie om bij de invoer van bestellingen gebruikt worden. Het model kan dan op basis van de ingevulde omschrijving en kenmerken van een bestelling een aantal CPV-codes voorstellen, waar de besteller een keuze uit maakt. Omdat het model niet zomaar in het financiële systeem geïntegreerd kan worden, kan hiervoor een applicatie ontwikkeld worden die op de achtergrond communiceert met zowel het model als het financiële systeem en zo beide samenbrengt. Dit vraagt echter om een uitgebreider traject en analyse, gezien de impact van deze aanpassing en het belang van het inkoopproces voor de continuïteit van het waterschapswerk.
Auteur: Peter Buisman









